JavaCC (Java Compiler Compiler - Metacompilador en Java) es el principal metacompilador en JavaCC, tanto por sus posibilidades, como por su ámbito de difusión. Se trata de una herramienta que facilita la construcción de analizadores léxicos y sintácticos por el método de las funciones recursivas, aunque permite una notación relajada muy parecida a la BNF. De esta manera, los analizadores generados utilizan la técnica descendente a la hora de obtener el árbol sintáctico.
Características
- Genera analizadores descendentes, permitiendo el uso de gramáticas de propósito general y la la utilización de atributos tanto sintetizados como heredados durante la construcción del árbol sintáctico.
- Las especificaciones léxicas y sintácticas se ubican en un solo archivo. De esta manera la gramática puede ser leída y mantenida más fácilmente. No obstante, cuando se introducen acciones semánticas, recomendamos el uso de ciertos comentarios para mejorar la legibilidad.
- Admite el uso de estados léxicos y la capacidad de agregar acciones léxicas incluyendo un bloque de código Java tras el identificador de un token.
- Los tokens especiales son ignorados por el analizador generado, pero están
disponibles para poder ser procesados por el desarrollador. - La especificación léxica puede definir tokens de manera tal que no se diferencien las mayúsculas de las minúsculas bien a nivel global, bien en un patrón concreto.
options {
Área de opciones
}
PARSER_BEGIN(NombreClase)
Unidad de compilación Java con la clase de nombre Nombreclase
PARSER_END(NombreClase)
Área de tokens
Área de funciones BNF
Área de opciones
}
PARSER_BEGIN(NombreClase)
Unidad de compilación Java con la clase de nombre Nombreclase
PARSER_END(NombreClase)
Área de tokens
Área de funciones BNF
El área de opciones permite especificar algunas directrices que ayuden a JavaCC a generar analizadores léxico-sintácticos bien más eficientes, bien más adaptados a las necesidades concretas del desarrollador. En el ejemplo se ha indicado que, por defecto, la gramática indicada es de tipo LL(1), excepto si, en algún punto, se
indica otra cosa.
Las cláusulas PARSER_BEGIN y PARSER_END sirven para indicarle a JavaCC el nombre de nuestra clase principal, así como para englobar tanto a ésta como a cualesquiera otras que se quieran incluir de apoyo, como pueda ser p.ej. un gestor de tablas de símbolos. En el ejemplo puede observarse que la clase principal constituye el analizador sintáctico en sí ya que la función main() crea un objeto de tipo Ejemplo a la vez que le pasa como parámetro en el constructor la fuente de la que se desea consumir la entrada: el teclado (System.in).
La clase creada por JavaCC incorporará una función por cada no terminal del área de reglas. Cada función se encargará de consumir la parte de la entrada que subyace debajo de su no terminal asociado en el árbol sintáctico de reconocimiento. Por tanto, asumiendo que el axioma inicial es listaExpr, una llamada de la forma miParser.listaExpr() consumirá toda la entrada, si ésta es aceptable.
Las siguientes dos áreas pueden mezclarse, aunque lo más usual suele ser indicar primero los tok ens y finalmente las reglas en BNF, especialmente por motivos de claridad en el código.
En el ejemplo se han indicado tokens de dos tipos. Los tokens agrupados bajo la cláusula SKIP son aquellos que serán consumidos sin ser pasados al analizador sintáctico; en nuestro caso son: el espacio, el tabulador, el retorno de carro (CR-Carry Return) y la alimentación de línea (LF-Line Feed).
Los tokens bajo la cláusula TOKEN constituyen los tokens normales, aunque el desarrollador también puede indicar este tipo de tokens en las propias reglas BNF, como ocurre con los patrones "(", ")", ";", etc. La declaración de cada token se agrupa entre paréntesis angulares y está formada por el nombre del token seguido por el patrón asociado y separado de éste por dos puntos. Los patrones lexicográficos se describen de forma parecida a PCLex. El ejemplo ilustra el reconocimiento de un identificador formado sólo por letras (ya sean mayúsculas o minúsculas merced al modificador [IGNORE_CASE] de la cláusula TOKEN) y de un número entero.
Opciones:
Las opciones más importantes son:
LOOKAHEAD
CHOICE_AMBIGUITY_CHECK
CHOICE_AMBIGUITY_CHECK
FORCE_LA_CHECK
STATIC
DEBUG_PARSER
BUILD_PARSER
IGNORE_CASE
COMMON_TOKEN_ACTION
UNICODE_INPUT
Tokens:
STATIC
DEBUG_PARSER
BUILD_PARSER
IGNORE_CASE
COMMON_TOKEN_ACTION
UNICODE_INPUT
Tokens:
JavaCC diferencia cuatro tipos de tokens o terminales, en función de lo que debe hacer con cada lexema asociado a ellos:
- SKIP: ignora el lexema.
- MORE: busca el siguiente el siguiente lexema pero concatenándolo al ya recuperado.
- TOKEN: obtiene un lexema y crea un objeto de tipo Token que devuelve al analizador sintáctico (o a quien lo haya invocado). Esta devolución se produce automáticamente sin que el desarrollador deba especificar ninguna sentencia return en ninguna acción léxica.
- SPECIAL_TOKEN: igual que SKIP pero almacena los lexemas de tal manera que puedan ser recuperados en caso necesario. Puede ser útil cuando se construyen traductores fuente-fuente de manera que se quieren conservar los comentarios a pesar de que no influyen en el proceso de traducción.
Anexos:

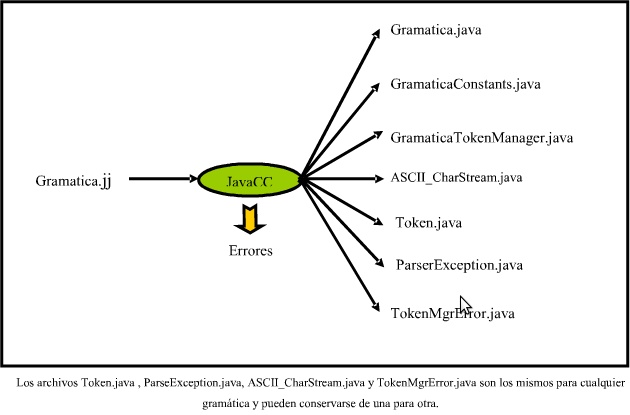
Enlaces:
Para descargar un tutorial completo de jFlex, Cup, JavaCC
No hay comentarios:
Publicar un comentario